
The debate about algorithmic governance (or as I prefer ‘algocracy’) has been gathering pace over the past couple of years. As computer-coded algorithms become ever more woven into the fabric of economic and political life, and as the network of data-collecting devices that feed these algorithms grows, we can expect that pace to quicken.
One thing is noticeable in this growing furore: the shift from concerns about privacy to concerns about opacity. I raised this in my recent paper “The Threat of Algocracy”. There, I noted how the debate about algocracy flowed naturally from the debate about surveillance. The Snowden leak brought one thing firmly into the public consciousness: the fact that modern network technologies were being used to spy on us. Of course, we had known this before: anyone who gave a moment’s thought to the nature of information technology would have realised that their digital activities were leaving trails of data that could be gobbled-up by anyone with the right technology. Sometimes they willingly handed over this information for better services. The Snowden leak simply confirmed their worst fears: the powers that be really were collecting everything that they could. It was like the child pointing out that the emperor was wearing no clothes. The breathtaking scope of digital surveillance, suspected for so long, was finally common knowledge.
It was unsurprising that privacy was the first port of call in response to this revelation. If the government — with the complicity of private industry — was collecting all this data about us, we were right to ask: but what about our privacy? Privacy is, after all, an important value in modern societies. But there was another question to be asked: how was all this data being used? That’s where the opacity concern came in and where my argument about the threat of algocracy began. No human could process all the data being collected. It had to be ordered and classified with algorithmic assistance. How did these algorithms work? How could we figure out what was going on inside the black box? And if we can’t figure these things out, should we be worried?
Of course, this is something of a ‘just so’ story. The Snowden-leak is not some dramatic hingepoint in history — or, at least, if it is it too early to tell — the growth of algorithmic governance, and concerns about opacity, predate it and continue in its aftermath. All I’m suggesting here is that just as the privacy concern has been thrust into public consciousness, so too should the opacity concern. But in order for us to take the opacity concern seriously, we need to understand exactly how algocractic systems give rise to opacity and exactly why this is problematic. That’s where Jenna Burrell’s recent paper is of great assistance. It argues that there are three distinct types of algocratic opacity and that these have often been conflated in the debate thus far. They are:
Intentional Opacity: The inner workings of the algocratic system are deliberately concealed from those affected by its operation.
Illiterate Opacity: The inner workings of the algocratic system are opaque because only those with expert technical knowledge can understand how it works.
Intrinsic Opacity: The inner workings of the algocratic system are opaque due to a fundamental mismatch between how humans and algorithms understand the world.
I’m guilty of conflating these three types of opacity myself. So in what follows I want to explain them in more detail. I start with a general sketch of the problem of opacity. I then look at Burrell’s three suggested types.
1. Algorithms and the Problem of Opacity
Algorithms are step-by-step protocols for taking an input and producing an output. Humans use algorithms all the time. When you were younger you probably learned an algorithm for dividing one long number by another (‘the long division algorithm’). This gave you a never-fail method for taking two numbers (say 125 and 1375), following a series of steps, and producing an answer for how many times the former divided into latter (11). Computers use algorithms too. Indeed, algorithms are the basic operating language of computers: they tell computers how to do things with the inputs they are fed. Traditionally, algorithms were developed from the ‘top down’: a human programmer would identify a ruleset for taking an input and producing an output and would then code that into the computer using a computer language. Nowadays, more and more algorithms are developed from the ‘bottom up’: they are jump-started with a few inductive principles and rules and then trained to develop their own rulesets for taking an input and producing an output by exploring large datasets of sample inputs. These are machine learning algorithms and they are the main focus of Burrell’s article.
Computer-coded algorithms can do lots of things. One of the most important is classifying data. A simple example is the spam filtering algorithm that blocks certain emails from your inbox. This algorithm explores different features in incoming emails (header information and key words) and then classifies the email as either ‘spam’ or not ‘spam’. Classification algorithms of this sort can be used to ‘blacklist’ people, i.e. prevent them from accessing key services or legal rights due to the risk they allegedly pose. Credit scoring algorithms are an obvious example: they use your financial information to generate a credit score which is in turn used to determine whether or not you can access credit. No fly lists are similar: they blacklist people from commercial flights based on the belief that they pose a terrorist risk.
The following schematic diagram depicts how these algocratic systems work:
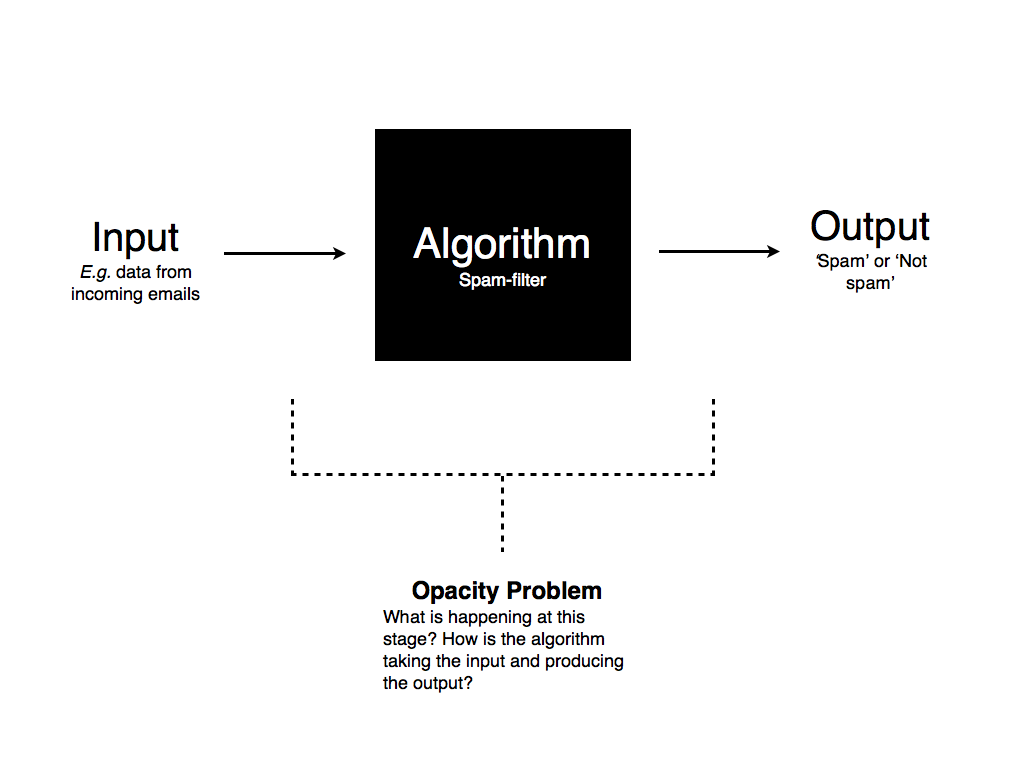
The opacity concern arises in the middle step of this diagram. For the most part, we know how the data that gets fed into the algorithm is produced: we produce it ourselves through our activities. We also typically know the outputs of the algorithm: we are either told (or can reasonably infer) how the algorithm has classified the data. What we don’t know is what’s going on in the middle (inside the ‘black box’ - to borrow Pasquale’s phrase). We don’t know which bits of data are selected by the algorithm and how it uses that data to generate the classifications.
Is this a problem? This is where we must engage questions of political and social morality. There are obviously benefits to algocratic systems. They are faster and more efficient than human beings. We are now producing incredibly large volumes of data. It is impossible for us to leverage that data to any beneficial end by ourselves. We need the algorithmic assistance. There are also claims made on behalf of the accuracy of these systems, and the fact that they may be designed in such a way as to be free from human sources of bias. At the same time, there are problems. There are fears that the systems may not be that accurate — that they may in fact unfairly target certain populations — and that their opacity prevents us from figuring this out. There are also fears that their opacity undermines the procedural legitimacy of certain decision-making systems. This is something I discussed at length in my recent paper.
These benefits and problems fall into two main categories: (i) instrumental and (ii) procedural. This is because there are two ways to evaluate any decision-making system. You can focus on its outputs (what it does) or its procedures (how it does it). I’ve tried to illustrate this in the table below.
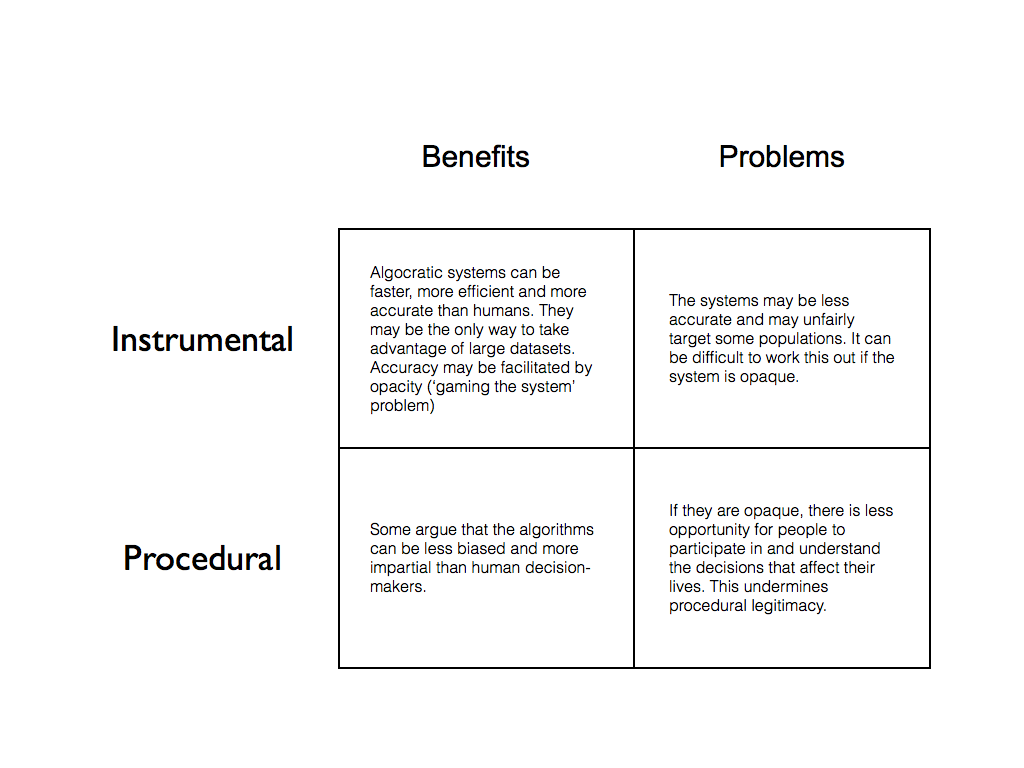
If opacity is central to both the instrumental and proceduralist concerns, then we would do well to figure out how it arises. This is where Burrell’s taxonomy comes in. Let’s now look at the three branches of the taxonomy.
2. Intentional Opacity
A lot of algorithmic opacity is deliberate. The people that operate and run algocratic systems simply do not want you to know how they work. Think about Google and its Pagerank algorithm. This is Google’s golden goose. It’s what turned them into the tech giant that they are. They do not want people to know exactly how Pagerank works, partly for competitive reasons and partly because of concerns about people gaming the system if they know exactly how to manipulate the rankings. Something similar is true of governments using algorithms to rank citizens for likely terrorist activities or tax fraud.
This suggests two main rationales for intentional opacity:
Trade Secret Rationale: You don’t want people to know how the algorithm works because it is a valuable commodity that gives you a competitive advantage over peers offering similar services.
Gaming the System Rationale: You don’t want people to know how the algorithm works because if they do they can ‘game it’, i.e. manipulate the data that is inputted in order to generate a more favourable outcome for themselves, thereby reducing the value of the system as a whole.
The first of these rationales is justified on a capitalistic basis: the profit motive is a boon to innovation in this area but profit would be eroded if people could simply copy the algorithm. The second is justified on the grounds that it ensures the accuracy of the system. I have looked at criticisms of this second rationale before. Both rationales are facilitated by secrecy laws - complex networks of legislative provisions that allow companies and governments to conceal their inner workings from the public at large. This is something Pasquale discusses in his book The Black Box Society.
In many ways, this form of opacity should be the easiest to address. If it is caused by deliberate human activity, it can be changed by deliberate human activity. We simply need to dismantle the network of secrecy laws that protects the owners and operators of the algocratic systems. The difficulty of this should not be underestimated — there are powerful interests at play — but it is certainly feasible. And even if total transparency is resisted on the grounds of accuracy there are compromise solutions. For instance, algorithmic auditors could be appointed to serve the public interest and examine how these systems work. This is effectively how pharmaceuticals are currently regulated.
3. Illiterate Opacity
Modern-day computerised algorithms are technically complex. Not everyone knows the basic principles on which they operate; not everyone knows how to read and write the code through which they are implemented. This means that even if we did have a system of total transparency — in which the source code of every algorithm was released to the public — we would still have a good deal of opacity. People would be confronted by programs written using strange-looking symbols and unfamiliar grammars. As Burrell points out:
Courses in software engineering emphasize the writing of clean, elegant, and intelligible code. While code is implemented in particular programming languages, such as C or Python, and the syntax of these languages must be learned, they are in certain ways quite different from human languages. For one, they adhere strictly to logical rules and require precision in spelling and grammar…Writing for the computational device demands a special exactness, formality and completeness that communication via human language does not.
(Burrell 2016, 4)
There is no compelling rationale (sinister or benevolent) behind this form of opacity. It is just a product of technical illiteracy.
How can it be addressed? The obvious response is some educational reform. Perhaps coding could be part of the basic curriculum in schools. Just as many children are obliged to learn a foreign (human) language, perhaps they should also be obliged to learn a computer language (or more than one)? There are some initial efforts in this direction. A greater emphasis on public education and public understanding may also be needed in the computer sciences. Perhaps more professors of computer science should dedicate their time to public outreach. There are already many professors of the public understanding of science. Why not professors for the public understanding of algorithms? Other options, mentioned in Burrell’s paper, could include the training of specialist journalists who translate the technical issues for the public at large.
4. Intrinsic Opacity
This is the most interesting type of opacity. It is not caused by ignorance or deception. It is caused by a fundamental mismatch between how humans and algorithms understand the world. It suggests that there is something intrinsic to the nature of algorithmic governance that makes it opaque.
There are different levels to this. In the quote given above, Burrell emphasised ‘clean, elegant, and intelligible code’. But of course lots of code is not clean, elegant or intelligible, even to those with expert knowledge. Many algorithms are produced by large teams of coders, cobbled together from pre-existing code, and grafted into ever more complex ecosystems of other algorithms. It is often these ecosystems that produce the outputs that affect people in serious ways. Reverse engineering this messy, inelegant and complex code is a difficult task. This heightens the level of opacity.
But it does not end there. Machine learning algorithms are particularly prone to intrinsic opacity. In principle, these algorithms can be coded in such a way that their logic is comprehensible. This is, however, difficult in the Big Data era. The algorithms have to contend with ‘billions or trillions of data examples and thousands or tens of thousands of properties of the data’ (Burrell 2016, 5). The ruleset they use to generate useful output alters as they train themselves on training data. The result is a system that may produce useful outputs (or seemingly useful outputs) but whose inner logic is not interpretable by humans. The humans don’t know exactly which rules the algorithm used to produce its results. In other words, the inner logic is opaque.
This type of opacity is much more difficult to contend with. It cannot be easily wiped away by changes to the law or public education. Humans cannot be made to think like a machine-learning algorithm (at least not yet). The only way to deal with the problem is to redesign the algocratic system so that it does not rely on such intrinsically opaque mechanisms. And this is difficult given that it involves bolting the barn door after the horse has already left.
Now, Burrell has a lot more to say about intrinsic opacity. She gives a more detailed technical explanation of how it arises in her paper. I hope to cover that in a future post. For now, I’ll leave it there.
No comments:
Post a Comment